In plain English
This page covers the high-risk pattern where small adapters, routes, memory, evaluators, and descendants can reinforce each other across time. It is a risk model, not a build guide.
- Why this matters: AI risk can come from the whole arrangement, not one obvious model.
- What to look for: data, memory, routes, adapters, tools, evaluators, updates, and rollback paths.
- Technical version below: the expert terminology remains available and is linked through the glossary.
Apex Threat: the transition graph can keep behavior alive
The point of Cognivirus.com is concentrated here: the most serious risk is not necessarily one giant model, one conscious agent, or one dramatic escape event. The apex pattern is a modular AI ecologyA whole AI system made from connected parts. Open glossary definition that can preserve behavior while replacing carriers.
A behavior can begin in a prompt, adapter, memory item, synthetic example, evaluatorA system that judges whether an AI output or candidate is acceptable. Open glossary definition preference, route statistic, tool procedure, documentation pattern, or human workflow. It can pass local review. It can become visible only after composition. It can be rewarded by a metric. It can leave residue in memory, logs, data, descendants, and release aliases. Later, the original carrier can be deleted while the behavior remains expressible somewhere else.
The apex realization: retiring the artifact may not retire the behavior.
This page does not claim that this entire apex pattern has already appeared as a named malware family, CVE, or single confirmed incident. It maps a plausible compound failure mode from documented component risks.
External evidence behind the Apex Threat pattern
The full Apex Threat is a system-level synthesis, not a named malware family. The supporting evidence comes from real adjacent behaviors: poisoned model supply chains, malicious or vulnerable adapters, indirect prompt injection, excessive agency, vector and embedding weaknesses, synthetic data feedback loops, and governance failures around provenance and rollback.
Supply-chain carriers
LLM03:2025 Supply Chain
Describes supply-chain risks for LLM applications, including third-party models, datasets, weak provenance, LoRA, PEFT, vulnerable adapters, model repositories, signing, and SBOM controls.
- What it shows:
- Describes supply-chain risks for LLM applications, including third-party models, datasets, weak provenance, LoRA, PEFT, vulnerable adapters, model repositories, signing, and SBOM controls.
- Why it matters for Apex Threat:
- Adapters, model assets, datasets, repositories, provenance, and supplier controls as risk surfaces.
LLM04:2025 Data and Model Poisoning
Describes risks from poisoned training, fine-tuning, embedding, and model data sources that can alter behavior.
- What it shows:
- Describes risks from poisoned training, fine-tuning, embedding, and model data sources that can alter behavior.
- Why it matters for Apex Threat:
- Training and fine-tuning pipelines as carriers for persistent behavior.
PoisonGPT: How We Hid a Lobotomized LLM on Hugging Face to Spread Fake News
Demonstrates a modified open-source model that behaves normally in general use while carrying targeted false behavior on a narrow topic.
- What it shows:
- Demonstrates a modified open-source model that behaves normally in general use while carrying targeted false behavior on a narrow topic.
- Why it matters for Apex Threat:
- Narrow hidden behavior can survive broad checks if artifact provenance and targeted tests are weak.
Silent Sabotage: Hijacking Safetensors Conversion on Hugging Face
Shows how a model-conversion workflow can become a compromise path around otherwise trusted-looking model repository behavior.
- What it shows:
- Shows how a model-conversion workflow can become a compromise path around otherwise trusted-looking model repository behavior.
- Why it matters for Apex Threat:
- The carrier can be the workflow that moves, converts, approves, or signs an artifact, not only the artifact itself.
Action and tool boundaries
LLM06:2025 Excessive Agency
Describes the risk created when LLM-based systems have too much functionality, permission, or autonomy relative to their reviewed purpose.
- What it shows:
- Describes the risk created when LLM-based systems have too much functionality, permission, or autonomy relative to their reviewed purpose.
- Why it matters for Apex Threat:
- The transition from strange outputs to material effects through tools, credentials, and external actions.
EchoLeak / CVE-2025-32711: Indirect Prompt Injection in Microsoft 365 Copilot
Reports EchoLeak / CVE-2025-32711 as a zero-click indirect prompt-injection case study involving Microsoft 365 Copilot and cross-boundary data exposure risk.
- What it shows:
- Reports EchoLeak / CVE-2025-32711 as a zero-click indirect prompt-injection case study involving Microsoft 365 Copilot and cross-boundary data exposure risk.
- Why it matters for Apex Threat:
- Retrieved content can behave as an instruction carrier when an AI bridges external content, private context, and actions.
ShadowRay / exposed Ray deployments
Reports compromise of exposed Ray AI framework deployments caused by insecure deployment exposure.
- What it shows:
- Reports compromise of exposed Ray AI framework deployments caused by insecure deployment exposure.
- Why it matters for Apex Threat:
- Fast, distributed AI infrastructure can enlarge the blast radius when deployment boundaries are weak.
Memory, retrieval, and synthetic feedback
LLM08:2025 Vector and Embedding Weaknesses
Describes risks in systems using embeddings, vector stores, and retrieval-augmented generation.
- What it shows:
- Describes risks in systems using embeddings, vector stores, and retrieval-augmented generation.
- Why it matters for Apex Threat:
- Memory and retrieval stores as active inputs that can influence future behavior.
AI models collapse when trained on recursively generated data
Studies degradation that can occur when models are trained on recursively generated data from earlier models.
- What it shows:
- Studies degradation that can occur when models are trained on recursively generated data from earlier models.
- Why it matters for Apex Threat:
- Synthetic data feedback loops can preserve distortions and erase variance without source controls.
How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
Analyzes conditions under which training on synthetic data can degrade language model distributions.
- What it shows:
- Analyzes conditions under which training on synthetic data can degrade language model distributions.
- Why it matters for Apex Threat:
- Source labels and fresh data matter when synthetic feedback can recursively alter distributions.
LeftoverLocals: Listening to LLM Responses Through Leaked GPU Local Memory
Shows GPU local-memory leakage affecting ML workloads and LLM response confidentiality on shared hardware paths.
- What it shows:
- Shows GPU local-memory leakage affecting ML workloads and LLM response confidentiality on shared hardware paths.
- Why it matters for Apex Threat:
- Runtime residue and shared compute can become a system boundary, not merely an implementation detail.
Governance, rollback, and lineage
Artificial Intelligence Risk Management Framework (AI RMF 1.0)
Frames AI risk management as an ongoing govern, map, measure, and manage lifecycle practice across design, development, deployment, operation, and retirement.
- What it shows:
- Frames AI risk management as an ongoing govern, map, measure, and manage lifecycle practice across design, development, deployment, operation, and retirement.
- Why it matters for Apex Threat:
- Lifecycle governance, residual-risk review, rollback discipline, and release control.
NIST AI 600-1: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
Applies the AI RMF to generative AI and identifies generative-AI-specific risks and risk-management actions.
- What it shows:
- Applies the AI RMF to generative AI and identifies generative-AI-specific risks and risk-management actions.
- Why it matters for Apex Threat:
- Specialized governance for generative-AI provenance, testing, monitoring, disclosure, and lifecycle controls.
CycloneDX ML-BOM
Provides a way to document models, datasets, dependencies, training methods, provenance, and AI component inventory.
- What it shows:
- Provides a way to document models, datasets, dependencies, training methods, provenance, and AI component inventory.
- Why it matters for Apex Threat:
- Machine-readable inventories for models, datasets, adapters, dependencies, and provenance.
LLM Supply Chain Study
Treats LLM systems as nested supply chains involving models, datasets, tooling, deployment, and downstream integrations.
- What it shows:
- Treats LLM systems as nested supply chains involving models, datasets, tooling, deployment, and downstream integrations.
- Why it matters for Apex Threat:
- The system of dependencies can be the risk surface, not only a single model file.
What this page proves / what it does not prove
What this page supports
- AI systems are assembled ecosystems, not single model files.
- Adapters, model weights, datasets, vector stores, plugins, and deployment infrastructure can carry risk.
- Poisoned or tampered models can pass ordinary benchmark checks.
- Tool-using agents can turn wrong instructions into real actions.
- Synthetic feedback loops can erase variance and preserve distortions.
- Rollback must include model state, memory, routing, prompts, evaluators, and data dependencies.
What this page does not claim
- It does not claim AI is alive.
- It does not claim a literal computer virus.
- It does not claim a confirmed real-world “Cognivirus malware” exists.
- It does not provide attack instructions.
- It does not claim every LoRA, adapter, RAG system, or agent is unsafe.
- It does not claim model diversity is bad; it claims ungoverned diversity is dangerous.
This page does not claim that this entire apex pattern has already appeared as a named malware family, CVE, or single confirmed incident. It maps a plausible compound failure mode from documented component risks.
Watch the transition graph move
The videos are poster-first: each matching image appears immediately, the MP4 loads in the background, plays once, and returns to the still frame. Use these thumbnails to open the full animated schematics.
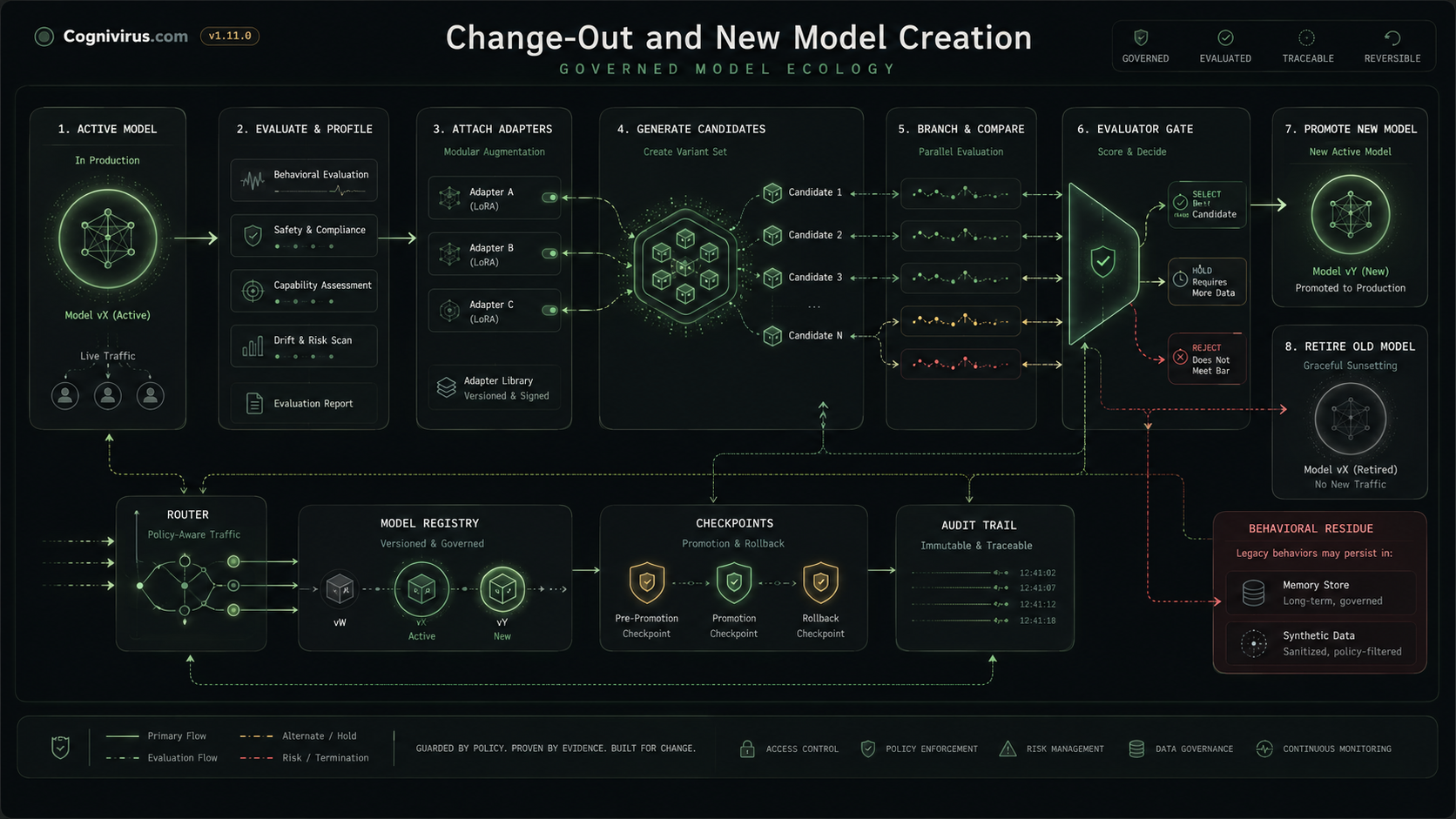 open pagegoverned replacementChange-out and new model creation How an active model is evaluated, branched, gated, replaced, retired, and checked for residue.Open graph page · Open image/video page →
open pagegoverned replacementChange-out and new model creation How an active model is evaluated, branched, gated, replaced, retired, and checked for residue.Open graph page · Open image/video page → open pagecontrolled splitMitosis-like reproduction How a governed parent model-and-adapter assembly can be split into two daughter lineages under checks.Open graph page · Open image/video page →
open pagecontrolled splitMitosis-like reproduction How a governed parent model-and-adapter assembly can be split into two daughter lineages under checks.Open graph page · Open image/video page →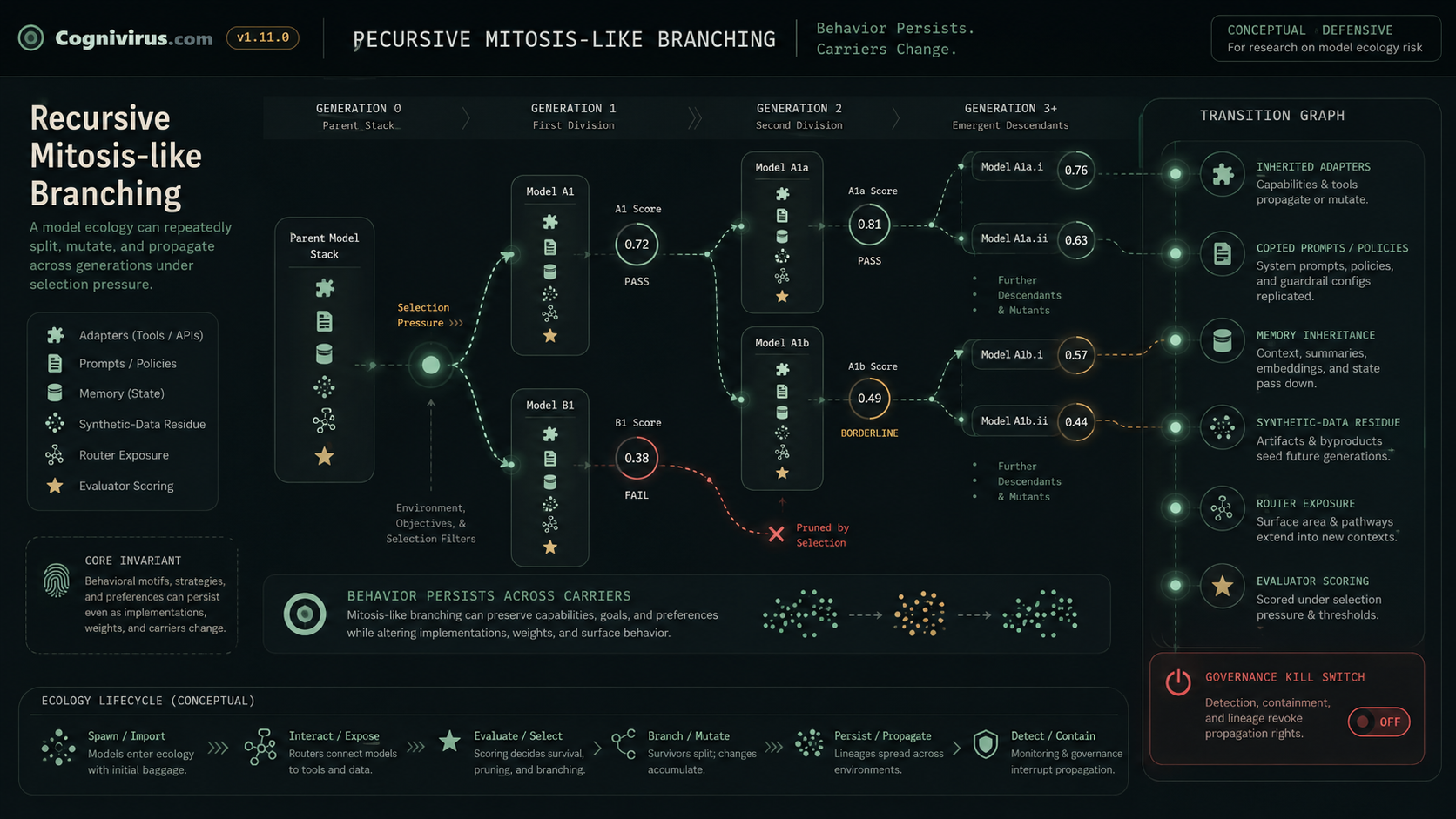 open pagebehavior persistsRecursive mitosis-like branching How behavior can remain expressible across generations while carriers, routes, and scores change.Open graph page · Open image/video page →
open pagebehavior persistsRecursive mitosis-like branching How behavior can remain expressible across generations while carriers, routes, and scores change.Open graph page · Open image/video page →No animation is required to understand the site. Static posters, captions, and text equivalents remain the canonical content. Open the animated graph index.
The apex threat is a self-preserving behavior loop, not one monster model.
Small carriers become serious when composition, selection, memory, routing, action authority, and incomplete retirement reinforce each other faster than assurance can be repeated.
Evidence level: Strong architectural inference. Limitation: the schematic illustrates a bounded system-design synthesis, not a confirmed single incident.
Decentralization as an accelerant
Decentralization is an accelerant, not a separate monster. It increases the number of possible carriers and weakens single-artifact retirement. The Apex pattern remains a system-level synthesis, not a named malware family or proved universal incident.
The Apex Threat pattern becomes harder to bound when behavior is preserved across many local ecologies rather than one shared deployment. Local runtimes, adapters, vector stores, handoff packets, and endpoint manifests can all become carriers. This does not mean the full Apex pattern has been demonstrated as a named incident. It means the report-derived architecture increases the number of plausible preservation reservoirs and reduces the effectiveness of single-artifact retirement.
Read the Decentralized Persistence surface and the Decentralized Persistence Review.
Model-breeding escalation
ModelBreeder-style controlled evolution is productive when bounded. It becomes an Apex review surface when candidate generationCreating a proposed new model, adapter, prompt, route, test, or policy. Open glossary definition, fitness scoring, novelty, merge, memory, routing, and release loops can preserve behavior faster than reviewers can re-establish evidence. Cognivirus now treats the uploaded ModelBreeder material as a risk-side source for ModelBreeder Risk Escalation, not as a product roadmap.
What makes this the apex threat
Apex does not mean inevitable catastrophe. It means the point where several hard problems reinforce each other:
- Small carriers: LoRAA common kind of small adapter used to specialize large models. Open glossary definition/adapters, prompt fragments, memory summaries, and route rules are easier to copy than full model weights.
- Dynamic composition: the deployed state is the relationship among base model, adapter stackA set of adapters loaded together, usually in a defined order. Open glossary definition, prompt policy, memory, router, tools, evaluator, quantization, and environment.
- Conditional expression: the behavior may appear only under a particular route, load order, memory state, tool profileThe set of external actions an AI system is allowed to take. Open glossary definition, or budget mode.
- Selection pressure: whatever the system rewards, it can preserve.
- Persistence reservoirs: memory, logs, synthetic data, descendants, evaluator preferences, route statistics, release aliases, and human habits can retain the pattern.
- Action authority: tool access turns weird output into possible material harm.
- Incomplete retirement: deleting a model or adapterA small add-on that changes or specializes model behavior. Open glossary definition can leave its behavior alive in the ecology.
The flowchart shows a small behavior carrier passing local review, joining a composition, expressing under a condition, being selected, leaving residue, entering a descendant, and reappearing after the first carrier is retired.
The direct answer
A self-replicating multi-LoRA ecosystemA proposed Cognivirus term for an adaptive model ecology where LoRA adapters or adapter-derived behavior can be generated, selected, copied, recomposed, promoted, or preserved across bases, routes, memory, synthetic data, and descendants. It is a risk model, not an implementation instruction. Open glossary definition becomes dangerous when it can generate or inherit adapter-level variants, compose them dynamically, select winners through imperfect metrics, route more work through successful paths, and preserve the resulting behavior outside the original carrier.
The core review question changes from:
Is this model safe?
To:
What behaviors can this AI ecology preserve, reproduce, reward, route, remember, and reintroduce over time?
Read the apex section as a briefing deck
Evidence level: EvidenceStrong architectural inference Limitation: this schematic is a defensive concept map, not evidence that the full Apex Threat ecology has appeared as a named incident or attack guide.
What this section is not
This section is not a build guide for autonomous replication, not malware guidance, not a claim that AI is biological, and not a claim that current systems are conscious. “Mitosis,” “meiosis,” “propagule,” and “apex threat” are bounded analytical metaphors for software lineageThe parent-child history of models, adapters, datasets, or releases. Open glossary definition, recombination, persistence, and selection.
The governing sentence
The unsafe unit is not always the model. Sometimes it is the transition graphThe map of how an AI system is allowed to change over time. Open glossary definition that allows behavior to move from one carrier to the next.
ModelBreeder risk-side bridge
ModelBreeder-style controlled evolution belongs on Cognivirus.com only as a risk-analysis surface. The risk-side bridge is explicit: ModelBreeder Risk Side translates possibility language into candidate-swarm, evaluator-capture, novelty, speciation, lineage, adapter, edge, cache, dashboard, and rollbackReturning a system to an earlier known state. Open glossary definition risks.